The Missing Half of the Equation
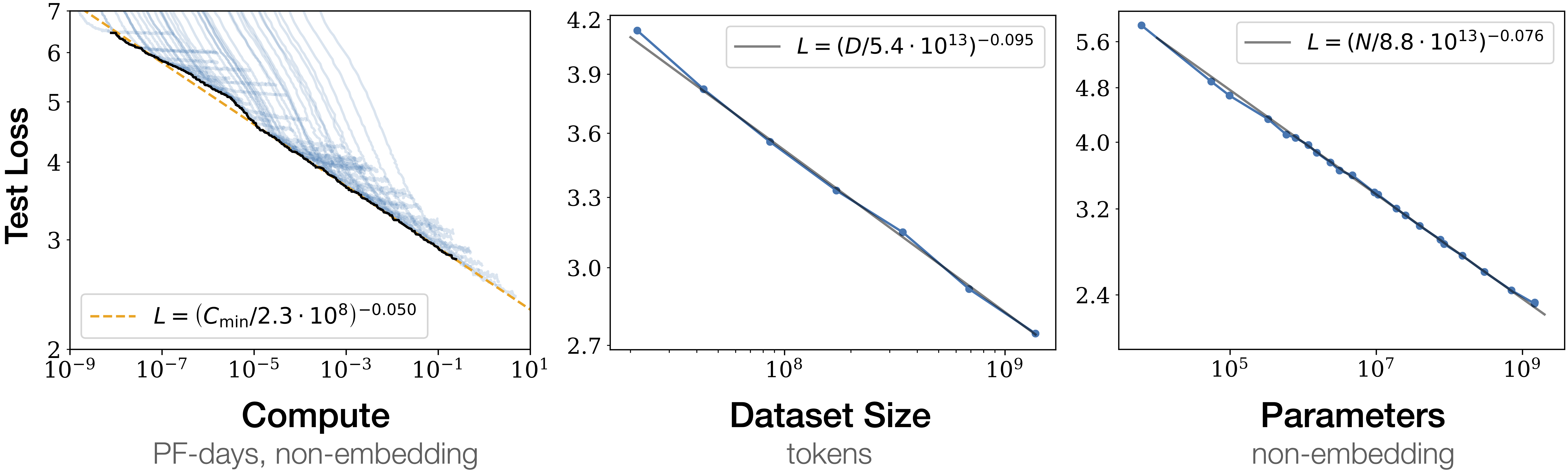
In AI research, scaling laws are gospel. Put in X more compute, get Y improvement in capability. The Chinchilla paper, the GPT-4 technical report, every major lab's internal planning documents—they all revolve around trying to develop these predictable relationships between resources and outcomes. Scaling laws are what is used to justify billion-dollar investments. They're why datacenters are being built at unprecedented scale.
We have scaling laws for the returns on investment in terms of capability yet we do not have similar normative models for how we believe widespread application of these technologies will change society. We are not running instructive small scale experiments on what a society with LLMs deeply woven in will look like.
To be clear from the outset: this is not an argument to slow down. It's that capability research has an empirical program, dedicated teams, and billion-dollar investment guided by predictive curves. Societal preparation has none of that. The argument here is for foresight, not restraint.
LLMs at scale could make institutions more contextually sensitive than they have ever been: capable of seeing people as individuals rather than averages, catching bad-faith exploitation that formal rules can never reach, delivering the judgment that scarcity of cognition forced us to compress into crude metrics. Or it could make them more totalizing and less escapable than anything that came before. Perfect enforcement, crystallized bias, Foucault's Panopticon fully realized, autonomy eroded not by malice but by optimization. LLMs could allow you to be seen as an individual. It also could mean you can never not be seen. Both outcomes are technically possible. This is with LLMs as they are now, imperfect inverse mechanical turks masquerading as oracles. Layers of probabilistic modeling stacked on top of each other. Superintelligence is not required for society to change drastically around this technology. This essay is not arguing that we are saved or we are doomed. It's arguing that we are deploying LLMs into institutions without the instruments to know which trajectory we're actually on.
Society is Built on Scarcity
Before the industrial revolution, physical labor was the scarce resource that organized everything—where people lived, how families worked, what children did, how authority was justified. The steam engine dissolved that scarcity, and the consequences weren't mainly economic: it forced into existence the modern city, compulsory education, the 8-hour workday, labor law, the welfare state. Not automatically—through generations of conflict and experiment. The disruption wasn't primarily about wages; it was about what kind of life was possible and what society was obligated to protect.
LLMs threatens to do the same to cognitive labor. Every institution we have is downstream of the assumption that cognitive work is scarce and therefore has to be rationed. Tax authorities audit a sample of returns because they can't audit all of them. Food safety inspectors sample products. Financial regulators examine a fraction of transactions. Courts process a fraction of disputes. The entire architecture of governance, markets, law, and expertise is built around one constraint: you cannot check everything, so you check enough to maintain trust. LLMs threatens to eliminate that constraint—not all at once, but directionally.
The industry's boldest response is Universal Basic Income: a stipend. UBI is a pure economic answer to what is not just an economic problem. It asks "how do people afford things" and ignores every harder question underneath: what do people do? What gives their lives structure? How do communities cohere? These are moral questions, not monetary ones—the same questions the industrial revolution forced into the open over decades of conflict, which we seem determined to defer again. If you can audit every tax return, what does the IRS look like? If cognitive expertise is no longer scarce, what do the institutions built around rationing it look like? Those aren't economic questions. They're questions about what governance is for.
More broadly, ordinary life has always depended on the practical limits of what can be known, tracked, or enforced. Society isn't just built around what rules say; it's built around what rules can reach. A family builds a deck without pulling permits because the permit process is expensive and their neighborhood isn't regularly inspected. A landlord rents a basement bedroom without an egress window in a city with a severe housing shortage because inspectors only respond to complaints, and nobody complains because the tenant needs the housing. Someone moves to a new city and quietly leaves a bad chapter behind them, because records didn't follow people the way they do now. A person asks a friend who happens to be a doctor for informal advice they couldn't afford to pay for officially. A small business owner asks a favor from someone they've known for years rather than going through a formal procurement process that would disadvantage them. None of these are heroic. They're just how life works when the cost of full compliance is high and the probability of being checked is low.
The same logic applies beyond individual choices. Communities develop informal economies around what official systems can't or won't serve: the neighbor who fixes cars, the informal childcare network, the loans between members of a family that doesn't involve a bank. Privacy itself has historically been less a right than a byproduct of practical obscurity: your medical history, your spending habits, your location throughout the day weren't tracked not because tracking was forbidden but because it was expensive. The gaps in visibility weren't accidental; they were structural, and people built lives inside them.
The intuition is that this is all a failure to be corrected. That if we could just enforce everything uniformly, things would be fairer and better. Sometimes that's true: selective enforcement often falls hardest on people with the least power to push back. But the gaps also do work that's hard to see until it's gone. They're how rules that don't quite fit get quietly negotiated. How communities absorb people who can't meet formal requirements but have nowhere else to go. How ordinary life remains livable under systems that were designed for an average case that doesn't describe everyone. LLMs doesn't just change enforcement; it changes the underlying structure of what can be known and tracked. The question isn't only what laws will be applied more uniformly. It's what kind of life is possible when practical obscurity disappears. Discord's 2026 age verification rollout is a mundane but clarifying example: a platform used by hundreds of millions of people decided that to access its full features, users would need to submit to a facial scan or upload a government ID to a third-party vendor. This happened six months after a breach exposed 70,000 users' government IDs and selfies from a previous verification vendor. The logic is not malicious. The platform has genuine obligations around age-gated content. But the infrastructure being built (verified identity required for full platform participation) is the same infrastructure that makes practical obscurity structurally impossible
What LLMs offers looks like comprehensive uniform governance but it's a black box that trades acknowledged incompleteness for hidden inconsistency. Training data biases, RL artifacts, distributional shift: these produce failures that aren't random and visible like under-sampling, but systematic and opaque, baked into weights no one can fully read. You've swapped a system that knew what it was missing for one that doesn't know what it's getting wrong. There is no avoiding the LLMs audit when the LLMs audit costs a few hundred dollars of compute.
There is also a less-noticed shift underneath all of this: a move from retrospective to live accountability. Every major institution of accountability we have built is fundamentally backward-looking. Courts reconstruct what happened. Regulators investigate past conduct. Auditors review historical records. Trials are an elaborate technology for producing a credible account of the past. The entire architecture of law assumes that what institutions can do is hold people accountable for what they have done: after the fact, episodically, at the cost of enormous effort. That retrospective character is a feature as much as a limitation: it means people live their lives forward, without continuous institutional observation, and face judgment only when someone decides to look.
LLMs changes that architecture. Not to the Minority Report model of predicting future crimes, but to something arguably more pervasive: live observation of the present. When every transaction, communication, and movement is processable in real time, institutions don't have to reconstruct what happened; they can watch it happening. This is the shift from episodic accountability to continuous monitoring. It has versions in both directions. The contextualizing version: harm gets caught as it compounds, not years later after a pattern has solidified beyond remedy. The totalizing version: people no longer have the slack of practical obscurity (the room to fail, recover, and move on that an episodic accountability architecture quietly provides). A juvenile record that a judge might have sealed gets embedded in a risk score. A period of financial difficulty that a loan officer might have contextualized becomes a permanent feature of a profile. The difference between those two versions isn't the technology. It's whether the governance layer is designed with the retrospective virtues in mind: that some forgetting is a feature, not a bug.
These aren't questions about who gets paid. They're questions about what institutions are for once the scarcity they were built to manage no longer exists. Jeremy Rifkin anticipated part of this in The Zero Marginal Cost Society (2014), arguing that near-zero marginal cost production would erode capitalism and give rise to a collaborative commons. His focus was economic: markets, ownership, profit. The institutional argument is deeper: it's not just that capitalism struggles when things become free, it's that governance itself was designed for a world where you couldn't check everything. James C. Scott's Seeing Like a State (1998) documents this exhaustively: states make society "legible" through simplification (standardized names, censuses, uniform measurement) because "no administrative system is capable of representing any existing social community except through a heroic and greatly schematized process of abstraction and simplification." Hayek made the point in The Use of Knowledge in Society (1945): knowledge is irreducibly dispersed, and no central authority can ever aggregate enough of it to fully govern. Decentralized, spot-check institutions aren't a design failure; they're a rational response to the impossibility of complete information. C. Thi Nguyen's The Score (2025) identifies the mechanism. Nguyen's worry is value capture: once you embed a person inside a scoring system, the metric tends to colonize the goal: you stop asking whether you're playing the game you actually want to be playing and start optimizing for the score itself. The mechanism that produces value capture also explains why institutions were built around metrics in the first place: numbers travel. A credit score can be processed by a thousand loan officers in a thousand cities; a nuanced assessment of someone's full financial situation cannot. Metrics strip context so that judgment can scale, and the stripping is the point. What looks like bureaucratic coldness is actually a scaling solution. The same logic governs all of it: sentencing guidelines, food safety thresholds, standardized testing, academic peer review, financial regulations. Every institution is a system for compressing contextual judgment into a portable signal, because the contextual judgment itself was too expensive to apply at scale. Society needs to be rebuilt around a world where the marginal cost of analysis, creation, and reasoning approaches zero. We haven't started. We're still running 20th-century institutions on 21st-century capability curves, and the gap is widening every year.
That gap is going to close one way or another. The question is what fills it. Metrics existed because contextual judgment didn't scale. Now it can. But "scalable contextual judgment" is a capability, not a value, and capabilities go in any direction. Replace the credit score with an AI that actually understands someone's financial situation: that could mean fairer lending, or it could mean lenders now have perfect information about every part of your life and no score you can improve. Replace the sentencing guideline with a model that weighs the full context of a case: that could mean fewer wrongful convictions, or it could mean a black box encoding every bias in the training data, with no written rule to challenge in court. Replace the spot-check audit with continuous analysis: that could mean catching systemic fraud earlier, or it could mean no one can afford to make a mistake because every mistake is now visible. The same dissolution of cognitive scarcity that makes individual judgment richer could make institutional reach total. Restoring the context that the metric always stripped away is one attractor. Replacing the metric's acknowledged incompleteness with a system that doesn't know what it's getting wrong is another. Which one we build is not a technical question. It's a governance one. And we haven't started asking it.
The industry is aware of this gap, at least in part. The alignment and safety community has spent years trying to govern AI's effect on society. The problem is where they chose to intervene: from the model out, not from society in.
Data As Law
In 1999, Lawrence Lessig argued in Code and Other Laws of Cyberspace that behavior online is regulated by four forces: law, norms, markets, and architecture. His warning was that code—the architecture of cyberspace—was becoming the most powerful of the four, and that unlike law, code has no appeals process. It just executes.
Law is fuzzy by design. It has context, interpretation, precedent, exceptions. A judge can decide that the letter of a statute doesn't apply to an unusual case. A jury can acquit on conscience. These aren't bugs—they're features, the accumulated wisdom that rigid rules applied without judgment produce injustice. Fuzziness is how law accommodates the infinite complexity of human situations.
Code is absolute. An if-statement doesn't care about context. A smart contract executes whether or not execution is fair. Bitcoin doesn't make exceptions. This is precisely what cypherpunks found appealing: rules that couldn't be bent by the powerful, enforced by math rather than men. Code as a replacement for trust in institutions.
The ideological throughline from Bitcoin to LLMs alignment is not accidental. Many of the same people, or at least the same type of people—rationalists, effective altruists, believers in formal systems over human judgment—migrated from crypto to AI safety carrying the same core intuition: that you can encode ethics into a system, that values can be specified precisely enough to be executed reliably. The dream is a Platonic one: a reasoning agent that receives principles and derives correct behavior from them the way a philosopher derives conclusions from premises. Write the right constitution, and the model applies it. The world's best virtue ethicist.
Anthropic's Constitutional AI is the most legible attempt at this. They literally wrote a constitution for Claude, a list of principles drawn from documents like the UN Declaration of Human Rights, and trained the model to critique and revise its own outputs against those principles. The name is deliberate: here are the values, encoded in text, now reason from them.
The problem is the model isn't doing what the framing implies. A constitution binds a reasoning agent that interprets and applies its principles. What Constitutional AI actually produced is a statistical model fine-tuned to generate outputs consistent with how constitutionally-flavored reasoning appears in text. Those are different things. The model doesn't derive behavior from the constitution the way a judge derives rulings from precedent. It produces outputs that pattern-match to what applying-this-constitution looked like in training data. In distribution, that can look indistinguishable from principled reasoning. Out of distribution, at genuine edge cases, novel cultural contexts, situations the rater pool never encountered, there is no logical guarantee. The constitution didn't bind the model. It shaped the weights. That gap is where the failure modes live.
The Three Laws of Robotics are the most famous fictional attempt at the same program, and the entire corpus of robot stories is a catalog of their failure modes. Not because the laws are badly written, but because the fuzziness they tried to eliminate keeps reasserting itself: every story finds a situation the laws didn't anticipate. Asimov spent decades demonstrating that you cannot specify human values precisely enough to execute them reliably, that a reasoning agent genuinely applying rigid principles will eventually encounter a case where the principles conflict or don't reach. LLMs aren't reasoning agents encountering edge cases in the laws. They're statistical models producing outputs that looked like reasoning in training, which is a subtler and harder-to-diagnose failure mode.
This points to something Lessig's framework didn't anticipate: in the world LLMs informed governance, data is law. The training corpus is the actual constitution. Whatever was overrepresented in the pretraining data, whatever the rater pool preferred, whatever got filtered in or out—those are the binding documents. They were never written down, have no preamble, nobody voted on them, and you cannot look them up. Constitutional AI wrote a visible constitution on top of a data constitution that already existed and was already shaping every output. The written one is the legible governance layer. The real one is hundreds of billions of tokens of human text, with all its biases and distributional skews baked into weights no interpretability technique can fully read.
Data-as-law has different properties from both of Lessig's categories, not strictly worse but with distinct failure modes. Code is deterministic and auditable: you can read the contract, find the bug, challenge the rule. Law is fuzzy and has appeals: the written text can be challenged, the edge case can go to court. Data-as-law is statistical and opaque: the outputs appear contextual, but the context-sensitivity isn't deliberate like a judge's, it's distributional, a reflection of what the training data happened to contain. The biases aren't in a rule you can find and argue against. They're in the shape of the distribution, invisible until they produce an outcome someone bothered to measure.
RLHF without an explicit constitution makes this worse: whatever the rater pool happened to prefer, their demographics, their instructions, their cultural assumptions, compressed into a reward signal with no written record of what was decided or why. The rater pool is the electorate. It's just one nobody voted to convene. The approach varies across labs; the shape is always the same: someone decides what the values are, encodes them through whatever mechanism they've chosen, and deploys the result without the public deliberation or democratic mandate that would be required of any analogous human institution.
This is their best attempt at governing AI's societal trajectory, and it operates entirely from the model out, not from society in. It does not ask whether LLMs is pushing institutions toward the contextualizing attractor or the totalizing one. It asks only whether the model behaves. Those are not the same question. And when LLMs with the capability to apply contextual judgment at institutional scale gets deployed, the question of whose context it's applying doesn't get answered by writing a better constitution. It gets answered by whoever controlled the training pipeline. The capability to scale judgment is value-neutral. What gets scaled is the data.
The Unintentional Regulator
The tech industry operates in a perpetual race. Capture the market before someone else does. Ship the feature before it's commoditized. Train the model before your competitor. Move fast and break things—the motto that defined an era and never really went away, they just have a different slogan now. This isn't a moral failing of individuals; it's game theory. If you don't capture the value, someone else will.
The most revealing case is Anthropic. They are, by their own account, the lab most convinced that they might be building one of the most dangerous technologies in human history. They built an entire Responsible Scaling Policy around the premise of not deploying models unless adequate safeguards exist. And then, under competitive pressure, they dropped the flagship pledge that was supposedly the whole point of the company. They operate in a Hegelian sense: the technology is inevitable, history has already decided, so the only meaningful choice is whether the people who take the risks seriously get there first. Existential concern about LLMs is now an argument for building faster, not slower.
Ironically, despite tens of thousands of words in think pieces on the implications of LLMs and entire research fields devoted to alignment and safety, the most effective governor on LLMs development turned out to be TSMC's N3 process yield rates. Not a law. Not a treaty. Not a democratically mandated pause. A semiconductor fabrication bottleneck and a lack of cheap electricity.
The primary constraint on LLMs scaling isn't regulation, isn't ethics boards, isn't democratic deliberation. It's Jensen Huang's production schedule. NVIDIA's Blackwell architecture shipped roughly 1.5 to 2 million units in 2025 not because anyone deliberated about whether society was ready, but because the wafers were ready. The number comes from wafer starts, lithography throughput, DDR5 yields at Micron, how many generators you can buy. The most consequential "LLMs governance" decision of 2026 was made in a fab in Hsinchu. Substation lead times in LLMs hotspots like Northern Virginia have stretched to as long as 72 months. Physical reality is doing what policy couldn't.
The throttle is controlled by manufacturing throughput, and the only reason it feels manageable is that the supply chain happens to be the bottleneck right now. That bottleneck is being engineered away on both sides of the geopolitical divide as aggressively as possible. The export controls that weaponize this bottleneck in order to slow China down are demonstrably not working: DeepSeek built frontier-competitive models on restricted chips by programming around their bandwidth limitations at a lower level than CUDA; the controls didn't slow them down, they forced an efficiency breakthrough. Huawei is planning to double Ascend LLMs chip output in 2026. When those constraints loosen, we'll discover that we never actually built a governance system. We just got lucky that the supply chain was the bottleneck first. When compute costs drop by a factor of ten (and despite the end of Dennard scaling, they likely will: the thermal power wall that ended clock speed gains in the mid-2000s hasn't stopped the cost-per-inference curve from falling, because the gains shifted from general-purpose transistor shrinks to architectural specialization, purpose-built silicon like TPUs and NPUs, and algorithmic efficiency of the kind DeepSeek demonstrated), what required a hyperscaler becomes feasible for a startup, then a hobbyist.
Crucially, supply chain physics don't resolve the tension; they only control the speed at which we approach it. Whether LLMs in institutions converges on the contextualizing attractor or the totalizing one is not a question wafer yields can answer.
The Laziness of Extinction Discourse
The community that should be asking 'which future are we building?' is asking a different question entirely. The popular public discussions about AI safety began with a focus on extinction risk: will superintelligent LLMs decide to eliminate humanity? Will we lose control of systems more capable than ourselves?
The focus on extinction is a failure mode disguised as rigor. It has the aesthetic of serious thinking (philosophical depth, civilizational stakes) while actually functioning as an escape hatch from the harder, messier, more tractable questions about the society we're building right now. Extinction is the one scenario where you don't have to do the institutional work, because if it happens there are no institutions left to fix. It's the most intellectually convenient possible framing.
Extinction is binary. We survive or we don't. It lets you skip the infinite gradations between "everything is fine" and "everyone is dead": where the actual future will lie. A world where LLMs works but democracy doesn't isn't an extinction scenario. Neither is a world of abundance and spiritual emptiness, where we solved AGI but not meaning. Neither is a world where the people building these systems made choices about whose values to encode without any democratic mandate, and we only noticed after the fact. These aren't edge cases. They're the likeliest futures. And extinction discourse has nothing useful to say about any of them.
There's also a practical problem: it's been a decade of serious public investment in x-risk as a framing, and the main thing it has produced is a community with a strong aesthetic identity and a negligible effect on actual deployment decisions. The labs that take existential risk most seriously, Anthropic, have sped up not slowed down. The framing has not generated the institutional responses or the governance infrastructure that would constitute taking it seriously. It has generated a lot of essays, a lot of funding for capability research disguised as safety research, and a career path for people who want to think about LLMs without thinking about any specific LLMs.
The deep questions about an AI-native society go unasked because they're hard and ultimately human-centered, not technological. Consider: the personal computer has existed for roughly 45 years, the internet has been mainstream for 30, and we're still working out their second and third-order effects: cybersecurity, mass data collection, algorithmically mediated media. The speculation was extensive: Alvin Toffler's The Third Wave (1980) anticipated the information society before the PC was widespread; Nicholas Negroponte's Being Digital (1995) predicted digital convergence with remarkable accuracy; Howard Rheingold's The Virtual Community (1993) mapped online social life before most people had experienced it; John Perry Barlow's "A Declaration of the Independence of Cyberspace" (1996) staked out the libertarian governance vision that still shapes platform policy today. We did not lack for vision. Yet there were still deeply disturbing unforeseen outcomes. And we are even blinder now in the era of LLMs.
LLMs at institutional scale could move society toward institutions that are finally able to hold contextual complexity, or toward institutions that are more totalizing and less escapable than anything we have built before. Extinction discourse has nothing useful to say about which of those we're headed toward, because both of them involve humans surviving.
The Moral Machine 1
The term borrows from MIT's Moral Machine experiment (Awad et al., Nature, 2018), which crowdsourced human moral judgments about autonomous vehicle decisions across millions of participants in 233 countries. The experiment revealed substantial cross-cultural variation in moral intuitions (who to spare in a trolley-problem-style crash) and is a systematic attempt to empirically map the terrain of human moral judgment at scale. Its lesson was not that moral consensus exists and can be extracted; it was that moral intuitions are culturally contingent, contested, and resistant to simple aggregation. Any "moral machine" faces that problem first.
Philip K. Dick's The Minority Report is an illustration of what algorithmic governance looks like at institutional scale: a pre-crime system that arrests people for murders they haven't committed yet, based on probabilistic prediction. The horror isn't that it's wrong; the predictions are largely accurate. The horror is what it means to live in a society organized around algorithmic certainty rather than demonstrated action. Guilt becomes statistical. Justice becomes actuarial. The system is more accurate than human judgment and also more inhuman.
Take a real judge. Today, judicial discretion is a feature, not a bug. Sentencing guidelines exist, but judges can depart from them. A first-time offender with extenuating circumstances gets treated differently than a repeat one. A prosecutor can decline to pursue a case they consider unjust. The system is leaky by design, because the alternative (rigid rule application without context) produces outcomes so obviously wrong that every legal tradition across history has built in escape valves. The same tension applies when LLMs allocates jobs, admits students, sets insurance rates, and decides parole, it could eliminate the nepotism and bias that currently shape these decisions. It could also calcify whatever assumptions were baked into training data, producing a more rigorous version of the same discrimination with less recourse. When a human rejects you, you can argue, appeal, find another human. When a system does, the decision feels categorical, produced by something that doesn't negotiate.
Less discriminatory hiring, more consistent sentencing: these could all be genuine improvements. But we would be arriving at them without the governance infrastructure to make them legitimate.
The problem Lessig identified used to cut both ways. Yes, encoding ethics into hard rules strips out the fuzziness that makes law humane. But fuzziness also has a cost, it was expensive to apply. Judgment takes time and expertise. You can't hire enough judges, regulators, or compliance officers to apply contextual reasoning at the scale that modern systems operate. So we defaulted to rules. Not because rules are better, but because rules are cheap.
That tradeoff is now shifting. We've had mechanisms for fuzzy judgment before. The jury is one. A group of peers, drawn from the community, asked not to apply a rule but to reach a verdict: to decide what a reasonable person would find. Lessig also points to deliberative polls: randomly sampled citizens given balanced information and time to discuss, whose considered opinions turn out to look quite different from snap poll responses. Both are attempts to extract something like collective moral judgment without reducing it to a rule. Both are expensive, slow, and impossible to scale. A jury deliberates for days over a single case. A deliberative poll costs millions and takes months. They work, in their domain. But you can't run a jury on every financial transaction or a deliberative poll on every norm violation.
However, Nguyen's diagnosis points directly at what's new here. The gap Lessig identified (between what law says and what norms expect) exists precisely because enforcing norms requires context, and context doesn't travel. The moment you formalize "exploiting the spirit of the rule," clever actors find a new way to comply with the letter of your formalization while violating its spirit. Every attempt to encode a norm into a rule just moves the gap. The underlying problem is that norms are about the whole situation (intent, pattern, effect, social meaning) and rules can only address specified features of situations.
What LLMs offer is a system that might hold context without collapsing it into a score. Not a metric, but something closer to the judgment that generates metrics: pattern recognition across entire situations, including the parts that didn't fit neatly into the rule. Norms are implicit, contextual, and hard to articulate, but not to an LLM trained on billions of examples of human communication about what's fair and what isn't. How do you write a regulation that catches someone acting in bad faith? You might not need to write it. You might be able to describe the situation and ask.
It's also worth being clear that the system described in the rest of this section (a moral machine capable of reliable contextual norm enforcement) does not currently exist but easy to imagine from current techniques and in no way requires general superintelligence to be convincing enough to deploy at scale.
Consider what this looks like in practice. High-frequency trading firms spend enormous resources finding strategies that are technically legal but structurally extractive; they don't buy and sell based on economic fundamentals, they arbitrage market microstructure in ways that impose costs on other participants without creating value. No specific rule is broken. Every individual transaction is legal. But the aggregate behavior is a kind of predation that most market participants would recognize as wrong if they could see it clearly. Rules-based regulation can't catch it because catching it requires reasoning about intent and effect across a pattern of behavior, not just checking whether individual transactions conform to specified constraints. The SEC issues guidance, adds new rules, watches the strategies mutate. It's an arms race that the regulators are structurally losing.
An LLM-based system asked to evaluate whether a trading strategy is fair (not whether it's legal) can reason about the question the way a thoughtful senior regulator would. Is this adding liquidity or extracting it? Is this participant providing a service to the market or imposing costs on it? Does the pattern, taken as a whole, serve or undermine the purpose markets are supposed to serve? These aren't algorithmic questions. They require the kind of contextual reasoning that formal systems have never been able to automate. Until now.
This opens something genuinely new: the possibility of identifying violations of norms rather than just laws. A "moral machine" that doesn't ask "did this actor violate rule 47(b)(2)?" but "did this actor behave in a way the community would recognize as wrong?" The difference is enormous. You could catch the tax lawyer who finds every loophole without breaking any rule. The company that technically complies with environmental regulations while deliberately undermining their intent. The landlord who never explicitly discriminates but systematically makes certain applicants' experience unpleasant enough to withdraw. These are norm violations that current law cannot reach: not because no one has tried to write the rules, but because the behavior is defined by context and intent that formal specification cannot capture.
This is not a simple good. Enforcing norms at scale means someone decides whose norms. The informal non-enforcement that allows communities to signal that a law is outdated, that makes space for civil disobedience, that permits the kind of friction where moral progress actually happens: that gets foreclosed too. A moral machine powerful enough to catch bad-faith exploitation is powerful enough to enforce consensus morality uniformly, without appeal, without exception. The same capacity that could fix high-frequency trading abuse could enforce social conformity. Foucault's Panopticon again, but now it's watching for spirit-of-the-rule violations, not just rule violations.
China's social credit system is the preview everyone points to. But what makes it troubling isn't really the LLMs; it's the values encoded in the system and the absence of any check on those values. An AI-mediated society with strong civil liberties, democratic oversight, and genuine recourse mechanisms would look different. The problem isn't LLMs in institutions. The problem is arriving at AI in institutions before you've built the oversight layer that makes it legitimate. We are doing the first without doing the second, at speed, across every institution simultaneously.
What the oversight layer would actually look like is worth speculating about concretely, because the abstract version ("democratic oversight," "civil liberties") doesn't do the work. Consider a different model: a standing deliberative assembly, convened not to pass a law but to build a model. Citizens, drawn like jurors from the community that will live under its decisions, spend weeks deliberating over the values they want encoded in the AI systems that govern them. What counts as fair hiring in this jurisdiction? What level of past conduct should stop counting against someone? When does pattern-of-behavior monitoring become surveillance? The outputs aren't statutes. They're preference specifications: training data, constitutional principles expressed in the form that AI systems can actually consume. Anthropic built Constitutional AI by having its researchers write a constitution. The democratic version of that is having the governed write it.
The mechanics already exist in scattered form. Citizens' assemblies have been used to deliberate on abortion law in Ireland, electoral reform in British Columbia, climate policy in France. Deliberative polls have extracted considered judgments on contested issues across dozens of countries. Constitutional AI has demonstrated that you can train a model to interpret and apply a written set of principles. The missing piece isn't any single technology or institution; it's the combination: a process with democratic legitimacy, feeding into a training pipeline, producing systems with the resulting dispositions, subject to ongoing audit and revision by the community that created them.
Such an institution would need several things that don't exist at scale: a methodology for converting deliberated preferences into training-compatible specifications; an auditing layer that verifies whether the resulting model reflects what the assembly actually decided; a revision process for when the model drifts or when the community's values change; and an appeals mechanism for individuals who believe the model's decision in their case violated the principles it was supposed to embody. None of that is technically impossible. What it requires is deciding that the legitimacy problem is real: that the question "whose values are encoded?" deserves a democratic answer rather than being settled by whichever research team's cultural assumptions happened to shape the reward model. That decision hasn't been made. The question hasn't even been seriously asked.
Meanwhile, the panopticon isn't a hypothetical—it's being assembled now, not through any deliberate plan but through a thousand independent procurement decisions nobody is watching. Predictive policing algorithms assign risk scores to neighborhoods and individuals. Automated systems adjudicate benefits eligibility, flag suspected fraud, set insurance rates. Courts use risk assessment tools in bail hearings and sentencing. Facial recognition runs in transit systems and public spaces. Palantir's Gotham platform, deployed across hundreds of law enforcement agencies, lets an officer start from a single name or license plate and retrieve email addresses, phone numbers, bank accounts, Social Security numbers, and family relationships, then auto-track every person in the resulting network. In 2025, ICE awarded Palantir a $30 million contract to build ImmigrationOS, integrating travel histories, biometrics, social media, Medicaid records, IRS data, and license-plate readers into unified AI-driven profiles on individuals, drawing on data from agencies with no legal mandate to share it for immigration enforcement. None of this is coordinated. Each piece was someone solving their own problem: the agency wanted better tools, the vendor had a product, the contract got signed. Aggregate them and you have the governance infrastructure described above—minus the legitimacy, the auditing, the revision process, and any democratic mandate. Most people living under it have no idea it's there. The totalizing attractor doesn't need a master plan. It just needs everyone to keep optimizing locally while no one asks what they're building together.
There is a version of this that resolves toward the contextualizing attractor, not the totalizing one, and Nguyen's framing helps see it clearly. The failure mode of metric-based institutions is that they treat people from different contexts as if context didn't exist: the same credit score formula applied everywhere, the same sentencing guideline regardless of circumstance, the same test score as the measure of a student. This produces a particular kind of injustice: technically consistent, contextually blind. The promise of AI-native institutions, properly governed, is something different: systems that can see context and still aspire to consistency. A sentencing model that can hold the full circumstances of a case and still be audited for disparate outcomes across race or class (the kind of structured algorithmic audit that Sandvig, Hamilton, Karahalios, and Langbort developed as a research methodology precisely for detecting discrimination in opaque systems). An admissions system that can evaluate a student's actual trajectory rather than their GPA, without the nepotism that currently fills the gap when human "holistic review" becomes cover for preference. These aren't guaranteed improvements. But they describe a real possibility that metric-based systems, by design, can never achieve: judgment that travels with its context rather than by stripping it away.
Conclusion
The accidental regulator (TSMC's yield rates, grid interconnection queues, the fact that 3nm lithography is hard) bought us time. We didn't earn it. Every efficiency breakthrough DeepSeek finds, every fab TSMC opens, every GPU off the production line is time running out on a clock we never started.
The public discourse about what to do with that time has been captured by the AGI question: will it be conscious? Will it take over? Will it kill us? These are the wrong questions, or at least not the urgent ones. The urgent ones are already in motion. Every institution that deploys an AI-based system is already operating under data-as-law, whether or not anyone named it that. The training corpus is already the constitution. The rater pool already convened. The values already encoded. The question of whether a system is "aligned" in the technical sense is a distraction from the question of what it's aligned to, and whose corpus, whose preferences, whose cultural assumptions got compressed into the weights it's running on.
This is the thing the extinction discourse spent a decade not asking. It isn't about superintelligence. It doesn't require AGI. It's happening with the systems that exist right now, at the scale they're deployed right now, in the institutions that are quietly replacing spot-checks and sentencing guidelines and benefits adjudications with models nobody voted to build. The facade of the AGI debate makes it easy to defer: we'll govern this once it gets serious. It's already serious. The governance gap isn't ahead of us. It opened the moment the first procurement decision was made.
The new rules aren't written down anywhere. That's the point. Data is law, and unlike every previous form of law, you cannot read it, cannot cite it, cannot challenge it in court. It has no preamble stating its purpose. It has no amendment process. It does not know what it got wrong. The cognitive scarcity that forced institutions to strip context out of judgment is dissolving, and the thing replacing it could finally restore that context — seeing people as individuals, holding complexity that averages always discard — or it could be the most complete instrument of control ever assembled, enforcing not just rules but norms, not just laws but the full shape of whoever's training data happened to dominate.
We don't know which. We haven't tried to find out. That's not an accident of timing. It's a choice, made implicitly, every day, by people building systems without asking the question and deploying them into institutions without the oversight layer that would make the answer legible. The gap between those two futures is not technological. Both are built from the same models. The difference is in what we decide the data is allowed to be law for — and whether anyone is watching when it decides.
Scaling laws for capabilities exist because someone decided to run the experiments: vary the compute, measure the loss, find the curve. We don't have societal scaling laws because we haven't run the equivalent experiments. Some of them are obvious enough to start. What happens when RLHF is treated like a vote — with franchise requirements, transparency, and an auditable record of what was decided? What does training data look like when it goes through a deliberative assembly instead of a contractor's annotation queue? What if democratic AI weren't a slogan but a methodology: citizens' assemblies that produce preference specifications, small-scale pilots in low-stakes institutions, iterated and measured? The point isn't that any of these would work. The point is that we don't know, because nobody is trying. The labs run thousands of ablations to understand what changes a model's capabilities. Nobody is running ablations to understand what changes a society's trajectory. That asymmetry isn't inevitable. It's just where we chose to put the resources.
Lots of different LLM based tools were used in the writing and research for this essay