ACM@UIUC GPU Cluster
In order to effectively work with deep learning a GPU is required. When I was an intern at NVIDIA, this wasn't a problem. NVIDIA maintains a massive GPU compute pool which is accessible to all its engineers (https://www.nvidia.com/en-us/data-center/dgx-saturnv/). It's harder when you don't work for the company who makes all the GPUs for deep learning, let alone a student. Y ou can try to use cloud providers like AWS or GCP but that costs money and is not as easy as running something locally. Having a large on site cluster is nice but you need to make sure that people using the cluster are able to work without interfering with each other.
ACM@UIUC was donated a couple GPUs from NVIDIA for setting up a chapter deep learning cluster. We then built out a machine which had 16 TB of disk space and these two GPUs installed as the first node in our cluster. The question was how to give people access in a way that was contained and controlled.
The Vault, root node of the ACM GPU Cluster
NVIDIA Docker and NGC
One of the large investments NVIDIA made in GPU software was adding an integration into docker (https://www.github.com/NVIDIA/nvidia-docker). This allows docker containers to access GPUs directly giving people a containerized workspace with GPU compute available. This is a nice way to host many people on one platform and make sure that no one accidentally bricks the system. Along with this docker extension NVIDIA released the NVIDIA GPU Cloud (https://ngc.nvidia.com). NVIDIA GPU Cloud is a registry of docker containers which pre package common deep learning environments and some provisioning software. This lets users who have Deep Learning Workstation Cards, DGX systems or who want to use NVIDIAs Cloud infrastructure to quickly set up workspaces and jobs to train their models. Users can upload a job in the form of a container, the data resources to mount and a command and then the NGC software will find an open GPU and start the run. Artifacts are then uploaded to the cloud service to be consumed.
NVIDIA GPU Cloud, a platform for sharing GPU compute resources amongst a team
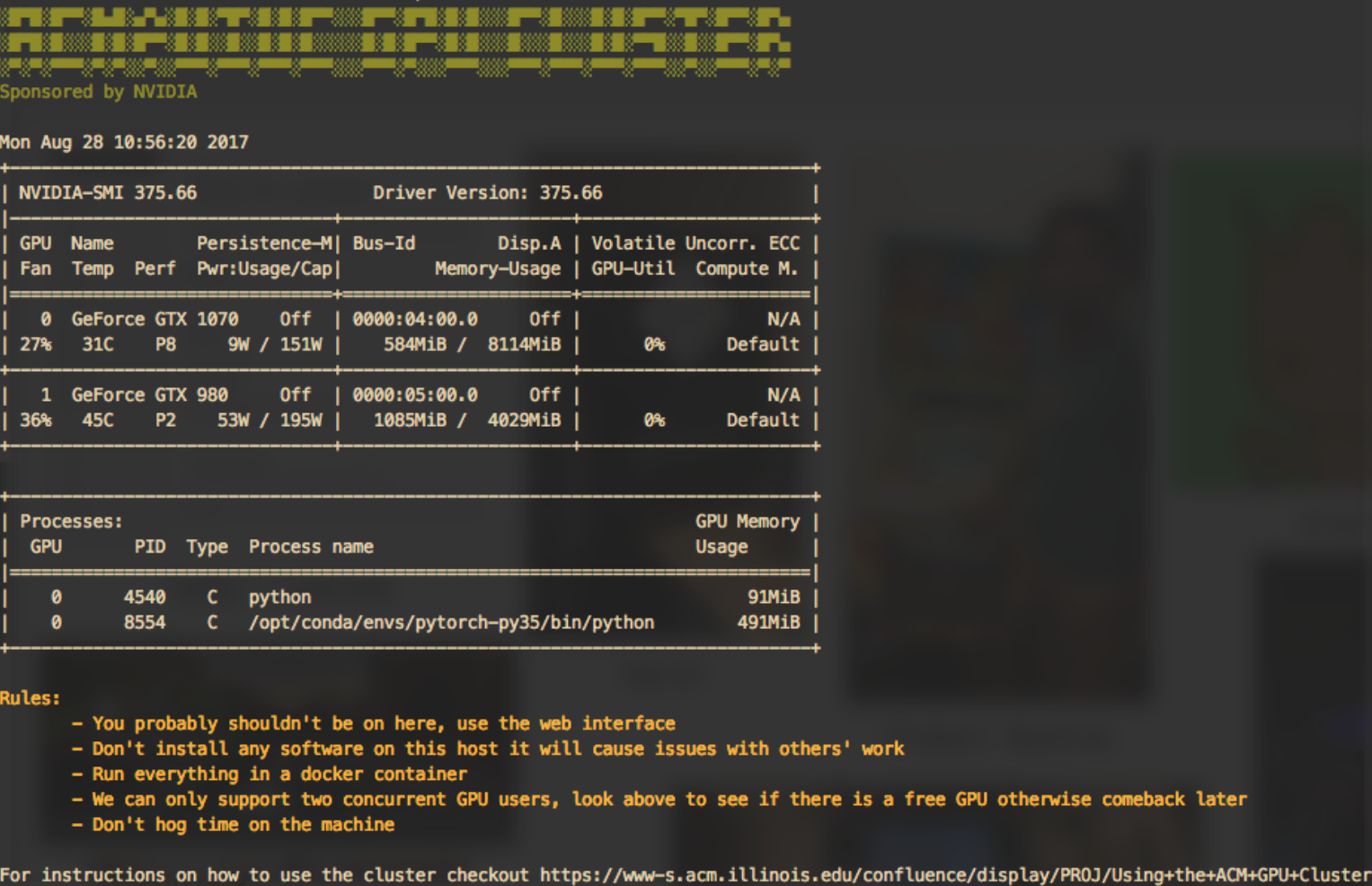
Because NGC is limited to paying customers or owners of $10.000 machines we decided to build a clone which anyone could run. Just like NGC it is based off of a repository of docker images and some software to launch containers. Unlike NGC which focused on batch jobs which makes sense for companies who are training massive networks, we wanted to focus on interactive jobs where people are developing code in the system for quick experiments (if they wanted to run a week long job AWS at that point serves them better).
The GPU Cluster
ACM GPU Cluster interface
PyTorch container environment information
We run a web server on the root node of the cluster which shows an interface that has a list of different container options for people to use. When a user selects one they are promoted to login with their ACM@UIUC credentials which lets us restrict users to just members. Then on the system a container is provisioned that is prebaked with the framework of their choice. This container also has a volume mounted which maps to the host machines 16TB data partition. There we keep peoples long term workspaces, and common datasets like ImageNet or COCO. This lets users restart work easily. Finally an open GPU is assigned to the container for the user. If there are no open GPUs then the user is told to come back later. Once the container is provisioned, the web interface directs users to a Jupyter interface which is running within the container. Here now users can run and create notebooks in their workspace or they can open up an in-browser bash shell as well.
Jupyter notebook interface once container has been provisioned
Integration with the ACM@UIUC infrastructure also allowed us to mediate usage and make sure people don't hog the system. The infra has a credit system which we use to monitor usage, if people run out of credits then jobs cannot be started until they have more.
This system was pretty successful, used for hackathon projects, class work and personal projects amongst many members in ACM. The GPU Cluster software is open source software and can be found here: